

Big Data and Apache Hivemall: Machine Learning with SQL
Anyone use Machine Learning techniques applied to data know very well that this is a complex task that require knowledge of many programming languages, science, framework, algorithms and it means not a short work.
With Hivemall, Apache provides a scalable library of machine learning that is built as a collection of Hive User Defined Functions that allow anyone to run algorithms of machine learning with knowledge of SQL. Hivemall runs on Hadoop-based data processing frameworks, a distributed file system, with MapReduce parallel data processing model in this ecosystem. It is possible to try these functionalities in Apache Hive or Spark environments.
Apache Hivemall, such as Google BigQuery ML, allows us to apply machine learning to our big data with a series of queries. These solutions introduce a new paradigm “machine learning in query language” and basically these have the same logical approach but Hivemall is more flexible in terms of selection of algorithms and platforms.
Stack diagram of Hivemall ecosystem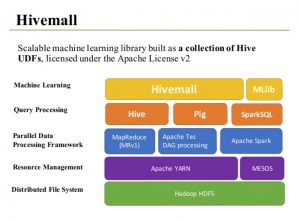
Follow these instructions to try Hivemall technology
Prerequisites
- Hadoop v2.4.0 or later
- Hive v0.13 or later
- Java 7 or later
- hivemall-all-xxx.jar
- define-all.hive (download here from official github)
Installation
Add the following two lines to your $HOME/.hiverc file.
add jar /home/myui/tmp/hivemall-all-xxx.jar;
source /home/myui/tmp/define-all.hive;
This automatically loads all Hivemall functions every time you start a Hive session. Alternatively, you can run the following command each time.
$ hive
add jar /tmp/hivemall-all-xxx.jar;
source /tmp/define-all.hive;
You can also run Hivemall on Apache Spark and Pig platform.
For Hivemall libraries and reference go at official Apache project at this link
